Google announced a breakthrough research in Natural Language Processing called Chain of Thought Prompting that raises the state of the art of advanced technologies like PaLM and LaMDA to what the researchers call a remarkable level.
The fact that Chain of Thought Prompting can improve PaLM and LaMDA at these significant rates is a big deal.
LaMDA and PaLM
The research conducted experiments using two language models, Language Model for Dialogue Applications (LaMDA) and Pathways Language Model (PaLM).
LaMDA is a model focused on conversation, like a chatbot but also can be used for many other applications that require speaking, dialogue.
PaLM is a model that follows what Google calls the Pathways AI architecture where a language model is trained to learn how to solve problems.
Previously machine learning models were trained to solve one kind of problem and they’d be set loose essentially to do that one thing really well. But in order to do something else Google would have to train a new model.
The Pathways AI architecture is a way to create a model that can solve problems that it hasn’t necessarily seen before.
As quoted in the Google PaLM explainer:
“…we’d like to train one model that can not only handle many separate tasks, but also draw upon and combine its existing skills to learn new tasks faster and more effectively.”
What it Does
The research paper lists three important breakthroughs for Chain of Thought Reasoning:
- It allows language models to break down complex multi-step problems into a sequence of steps
- The chain of the thought process allows engineers to peek into the process and when things go wrong, this allows them to identify where it went wrong and fix it
- Can solve math word problems, can accomplish commonsense reasoning and according to the research paper can (in principle) solve any word-based problem that a human can.
Multi-step Reasoning Tasks
The research gives an example of a multi-step reasoning task that language models are tested on:
“Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
A: The cafeteria had 23 apples originally. They used 20 to make lunch. So they had 23 – 20 = 3. They bought 6 more apples, so they have 3 + 6 = 9. The answer is 9.”
PaLM is a state of the art language model that is part of the Pathways AI architecture. It is so advanced it can explain why a joke is funny.
Yet, as advanced as PaLM is, the researchers claim that the Chain of Thought Prompting significantly improves these models, and that’s what makes this new research so worthy of taking note of.
Google explains it like this:
“Chain of thought reasoning allows models to decompose complex problems into intermediate steps that are solved individually.
Moreover, the language-based nature of chain of thought makes it applicable to any task that a person could solve via language.”
The research paper then goes on to note that standard prompting doesn’t really improve when the scale of the model is increased.
However with this new approach scale has a significant and notable positive impact on how well the model performs.
Results
Chain of Thought Prompting was tested on both LaMDA and PaLM, using two mathematical word problem datasets.
- GSM8K
- MultiArith
These datasets are used by researchers as a way to compare results on similar problems for different language models.
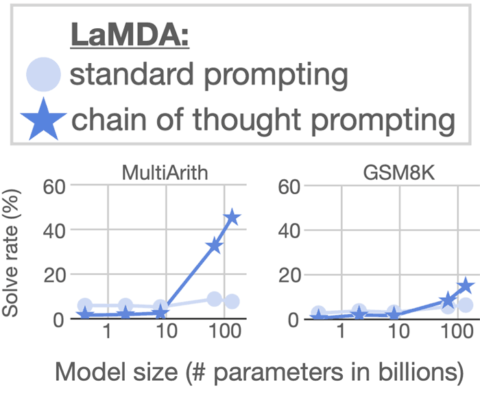
Below are images of graphs showing the results of using Chain of Thought Prompting on LaMDA.
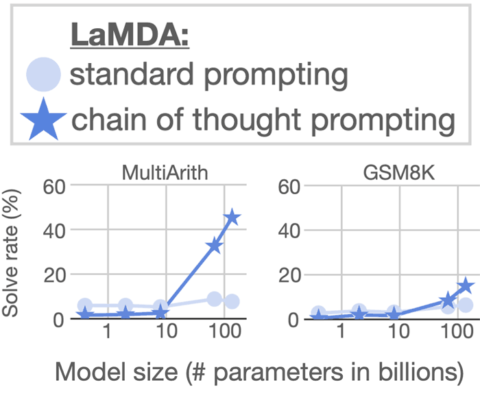
The results of scaling LaMDA on the MultiArith dataset shows that it resulted modest improvement. But LaMDA scores significantly higher when scaled with Chain of Thought Prompting.
The results on the GSM8K dataset show a modest improvement.
It’s a different story with the PaLM language model.
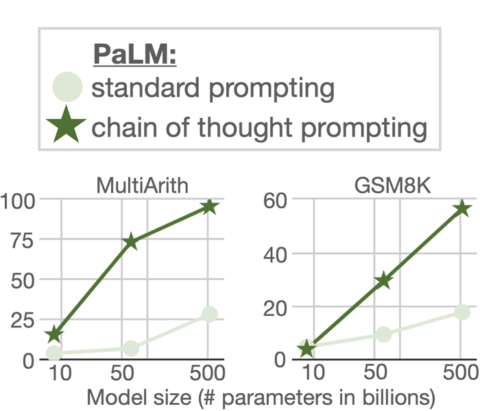
As can be seen in the graph above the gains from scaling PaLM with Chain of Thought Prompting are huge, and they are huge for both datasets (MultiArith and GSM8K).
The researchers call the results remarkable and a new state of the art:
“On the GSM8K dataset of math word problems, PaLM shows remarkable performance when scaled to 540B parameters.
…combining chain of thought prompting with the 540B parameter PaLM model leads to new state-of-the-art performance of 58%, surpassing the prior state of the art of 55% achieved by fine-tuning GPT-3 175B on a large training set and then ranking potential solutions via a specially trained verifier.
Moreover, follow-up work on self-consistency shows that the performance of chain of thought prompting can be improved further by taking the majority vote of a broad set of generated reasoning processes, which results in 74% accuracy on GSM8K.”
Conclusions
The conclusion of a research paper is one of the most important parts to check for understanding if the research advances the state of the art or is a dead-end or needs more research.
Google’s research paper conclusion section has a strongly positive note.
It notes:
“We have explored chain of thought prompting as a simple and broadly applicable method for enhancing reasoning in language models.
Through experiments on arithmetic, symbolic, and commonsense reasoning, we find that chain of thought processing is an emergent property of model scale that allows sufficiently large language models to perform reasoning tasks that otherwise have flat scaling curves.
Broadening the range of reasoning tasks that language models can perform will hopefully inspire further work on language-based approaches to reasoning.”
What that means is that Chain of Thought Prompting may have the potential to provide Google with the ability to significantly improve their various language models, which in turn can lead to significant improvements in the kinds of things Google can do.
Citations
Read the Google AI Article
Language Models Perform Reasoning via Chain of Thought
Download and Read the Research Paper
Chain of Thought Prompting Elicits Reasoning in Large Language Models (PDF)
Go to Source
Author: Roger Montti